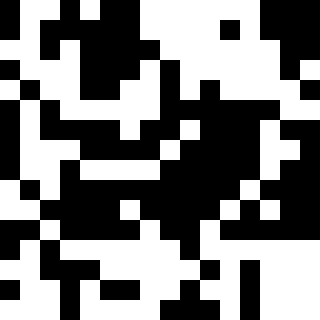
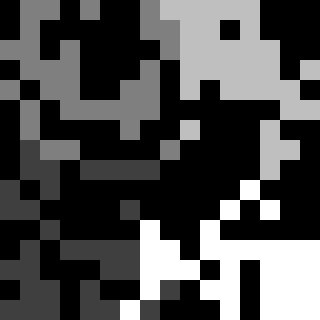
The goal of this CUDA or OpenCL project is to implement a non-trivial parallel program... in this case, using a Steady State Genetic Algorithm (SSGA) to partition the nodes of a graph into k partition elements such that the sum of weightings between nodes within the same partition element is minimized. More precisely, the weightings will be taken by computing distances between nodes -- non-black pixels -- in a simple PGM (Portable Gray Map) image given as input. The output will be another PGM image, but using k non-black colors to indicate to which partition element each node has been assigned.
Yes, you may use either CUDA or OpenCL -- your choice.
Although we have discussed it in class, I don't expect you to know much about GAs. As a general rule, although a little domain-specific understanding can help, you shouldn't need to know much about the theory behind a program in order to port and optimize the code for a different architecture. So, here's the serial reference code:
This code should be compiled by something like:
cc a2serial.c -o a2serial -O2 -lm
The input image is given on stdin and the output result goes to stdout, but there are several command line parameters needed as well. The first is k, the number of partition elements or colors to use. The next is the population size. The following two parameters give the relative frequency of crossover and mutation; only the ratio between these two integers matters. The final argument is the number of "generations" to search, which for an SSGA is really the total number of individual possible solutions to consider. That number should always be greater than the population size. Selecting good values for the parameters can be tricky, so consider as a starting point something like:
./a2serial 4 100 1 1 100000
Sample input and output files are linked to the following PNG files (but you must use the PGM files, not the PNGs!):
You may parallelize this code in any way that you wish. However, I would expect that, after the first project, you take advantage of the fact that there is an optimal number of virtual processing elements to run with on the GPU. One of the nice features of GAs is that parameters like population size are essentially free choices, so it is very easy for you to tweak things to get the exact degree of parallelism that you want.
One of the hardest parts of this involves the generation of random numbers in parallel. As discussed in class, you can use a very simple generator of the form:
rand = (a * rand) % m
If m is 2 to the 32nd power, the modulus is a free operation, since a 32-bit integer value is naturally clipped that way. In such a case, a decent choice of the value for a is ((8 * 16807) + 5). Of course, the bottom few bits don't look very random, so you'll probably want to ignore some of the least significant bits rather than using the rand value directly.
That generator by itself would give the same value sequence for every processing element. Instead, you can use the same seed for all processing elements, but also use the trick that for NPROC virtual processing elements, you start each processing element with
rand = (b * seed) % m
where b is a to the IPROC power. Each processing element then substitutes a to the NPROC power for a in the original formula.
You will be submitting source code, a make file, and a simple HTML-formatted "implementor's notes" document which also should summarize your findings.
Your project is due the day of the final exam, December 12, 2011.. Submit your tar file here:
 GPU Computing
GPU Computing